A $1.3M OpenAI bill from one of its own engineers just gave the market the empirical number it has been missing all year. Autonomous agents are not $20/month tools when they run continuously.
For the last twelve months, every AI provider has been selling autonomous coding agents the same way.
“Start at $20 a month.” “Save hours every day.” “Replace tedious work.” “Boost developer productivity.”
The pricing pages all converge around the same comfortable number. Twenty dollars. Two hundred dollars at the top end. Affordable enough that nobody asks the next question.
The next question is the one this post is about.
What does it actually cost to run an autonomous coding agent continuously, in production, on workloads that are not toy demos?
For most of 2025, nobody could answer that. The pricing pages quoted human-paced numbers. The vendor case studies hid behind enterprise NDAs. The agentic coding hype cycle ran ahead of the actual data.
That changed in May 2026…
A single screenshot, posted publicly by Peter Steinberger — founder of OpenClaw, now at OpenAI, gave the market the empirical number it had been missing all year!!!
The number is not pretty
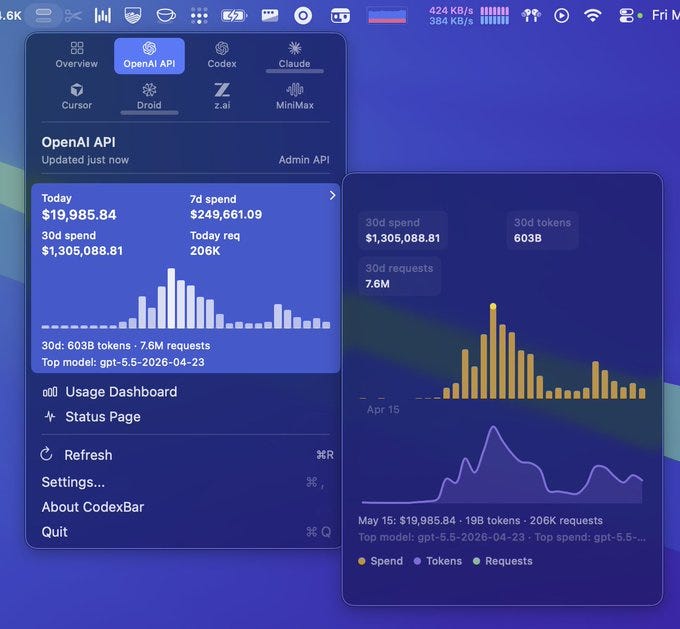
The Receipt
30 days of OpenAI API spend. $1,305,088.81 billion tokens. 7.6 million requests. Top model GPT-5.5
Steinberger is not some random AI engagement account.
He bootstrapped PSPDFKit for a decade, built it into the standard mobile PDF library running on over a billion devices, raised $116M from Insight Partners, then quietly left to build agents. OpenClaw is now the fastest-growing open-source project in GitHub history with over 302,000 stars — past React, Vue, and TensorFlow.
He joined OpenAI in February 2026.
His three-person team is running approximately 100 Codex instances continuously.
These are not idle agents waiting for cute prompts. They are reviewing PRs, scanning commits for security issues, deduplicating GitHub issues, writing fixes, monitoring benchmarks, posting regressions to Discord, opening PRs based on meeting transcripts.
Steinberger described what he is doing as research.
“How would we build software in the future if tokens don’t matter?”
The internet did what the internet always does. Some called it a flex. Some called it marketing. Some did the salary math. Some accused him of shipping nothing. He fired back: “You seem to have a very particular definition of nothing.”
The takes are everywhere. The math is nowhere.
The question nobody is answering is the only one that actually matters.
If this is what a serious agent fleet costs at scale, what does it mean for the rest of us paying our own bill?
The Number That Should Be On A Sticky Note
$1,305,088.81 ÷ 100 agents ÷ 30 days = $435 per agent per day.
Annualised monthly: about $13,000 per agent per month.
That sounds insane…
Run that math again.
$300,000 ÷ 100 agents ÷ 30 days = $100 per agent per day. About $3,000 per agent per month.
It is closer to $3,000 to $13,000 per agent per month, depending on speed mode and workload.
That is probably the most useful AI cost benchmark developers have been given this year. Not theory. Not “starts at $20/month.”
Actual agent burn.

The Table Nobody Wants On A Pricing Page
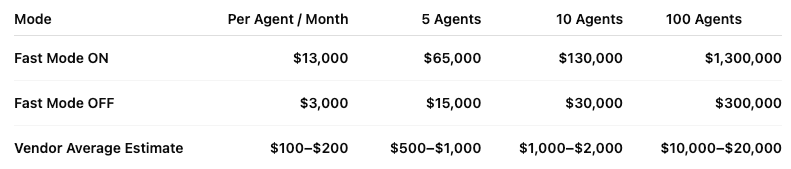
The gap between the vendor row and the Steinberger rows is the whole story.
Because there is a real difference between AI assistant used by a human and autonomous agent running continuously.
Those are not the same product. They should not be priced like they are.
Cost Truth 1: Subscription Pricing Was Never Built For Agents
Flat subscriptions were designed for human-paced usage.
You open the editor. You ask for help. You wait. You review. You prompt again. A $200/month Codex Pro plan or Claude Max-style plan makes complete sense in that loop.
Agents do not behave like humans.
Agents loop. Agents retry. Agents read the same file ten times. Agents call tools while you sleep. The token burn does not pause for coffee breaks.
A human developer using AI 4–6 hours a day is one thing. A fleet of agents running thousands of calls per day is completely different.
This is why providers are already tightening the walls.
When Anthropic restricted third-party agent frameworks from running on standard Pro and Max subscriptions last month, the press cycle framed it as a crackdown.
It was not a crackdown. It was economics catching up to subscription marketing.
Anthropic concluded correctly, that the compute demands of autonomous agents were unsustainable at flat-rate pricing. They introduced separate programmatic-use budgets billed at full API prices.
OpenAI made the opposite bet. They opened ChatGPT subscriptions to OpenClaw’s 3.2 million users at $23/month, letting them run autonomous agents through the Codex endpoint.
Anthropic is saying “we cannot subsidise this.” OpenAI is saying “we will subsidise this long enough to win the platform war.”
Both companies are right about their own incentives. Neither is sustainable as a permanent pricing model.
And here is where the Steinberger receipt STOP being someone else’s problem and starts being YOURS…
You are on the $20 Claude plan, or the $200 Codex Pro plan, and Steinberger spent $1.3M on research that has nothing to do with you. Why should the per-agent math matter to a subscription user?
It matters because you are already paying for it. You are just paying with limits instead of dollars.
Think about the trajectory…
When Codex and Claude Code launched, there were no session limits. None. You opened the tool, you used it. Then the 5-hour session window arrived. Then the weekly limit. Then the l_imit dropped_. Then it dropped again. Then the peak-hour throttling started.
Neither provider has officially acknowledged the tightening. Anyone on a Pro plan for more than three months has felt it.
That tightening is not a “BUG”
A subscription is a fixed-price contract. The provider takes the risk that your usage stays inside their cost envelope. When agentic workflows blew that envelope open, the providers did not raise prices openly. They reduced what a $20 or $200 plan actually delivers.
QUIET INFLATION…
The migration pattern you are watching in real time is the result. Users on $20 Claude plans have been moving toward $20 Codex plans because Codex’s session and weekly limits still feel generous by comparison.
That generosity is OpenAI’s platform-war subsidy. It has a shelf life. The limits on Codex are already shrinking too, just on a delayed schedule.
The path that almost nobody is naming out loud is the price ladder underneath all of this:
- The $20 plan you are on today becomes the $40 plan next year
- The $200 plan becomes the $400 plan
- The “Pro tier” gets renamed “Pro Plus tier” and a new entry tier shows up below it at the old price point with half the limits
You do not need to run 100 agents to feel this. You just need to keep using AI seriously for another twelve months.
That is why Steinberger’s bill matters to a subscription user. Because the economics his receipt exposed are the same economics quietly tightening your weekly limits right now. The number is loud at his scale and silent at yours.
It is the same number.
If you are building your workflow around a flat-rate subscription assumption, you are building on sand. The cost normalisation is coming. Plan for it now or get surprised when your Q3 limits feel half as generous as your Q1 limits did.
Cost Truth 2: Fast Mode Is A Silent 4x Multiplier
The most useful number inside Steinberger’s bill is not $1.3M.
It is the gap between fast mode and standard mode.
Fast Mode ON: $13,000 per agent per month. Fast Mode OFF: $3,000 per agent per month.
Roughly a 4x cost difference. Same agents. Same workload. Same direction of output. Different execution mode.
For Steinberger at OpenAI’s expense, the multiplier does not matter. He turned it on because speed was worth more than cost when cost was zero to him.
For you on your own credit card, the multiplier is the difference between a $3K/month agent and a $13K/month agent.
Same agent. Same outputs. Different cost ladder.
Fast Mode makes sense for production incidents, urgent fixes, demos, and tasks where delay is more expensive than token burn.
For continuous background work—the kind most agent fleets actually do, standard mode is the correct default.
Most background agents do not need to be fast. They need to be affordable.
That one line can save you thousands of dollars this quarter.
Nobody at OpenAI is going to put this in a blog post because it would tell you to spend less money. Steinberger told you accidentally, by being transparent about his own numbers.
Cost Truth 3: Attribution Is The Bottleneck, Not The Bill
This is the part most people are still not talking about.
Steinberger’s bill is 100% attributable by accident. His feature is OpenClaw. His team is three people. The agent fleet has one obvious purpose. When the bill says $1.3M, you can roughly say “that money went into OpenClaw research.”
Most developers do not have that CLARITY!
Most teams have AI usage scattered across Cursor, Claude Code, Codex, Gemini, local scripts, CI agents, random prototypes, and abandoned branches.
At the end of the month, they know the total bill. They do not know where the money actually went.
The important question is no longer _“how much did I spend on AI?” _The better question is “which feature consumed that spend?”
A dashboard that says “you spent $210 this month” is useful.
A dashboard that says “$74 went into auth refactor, $41 went into billing bugs, $28 went into dead-end UI work, and $19 went into a branch you deleted” that is where things actually become useful.
The era of treating AI spend as a fixed subscription line item is closing. The era of treating it as a P&L category, with attribution and audit and per-feature rollups, is opening.
That is the missing layer.
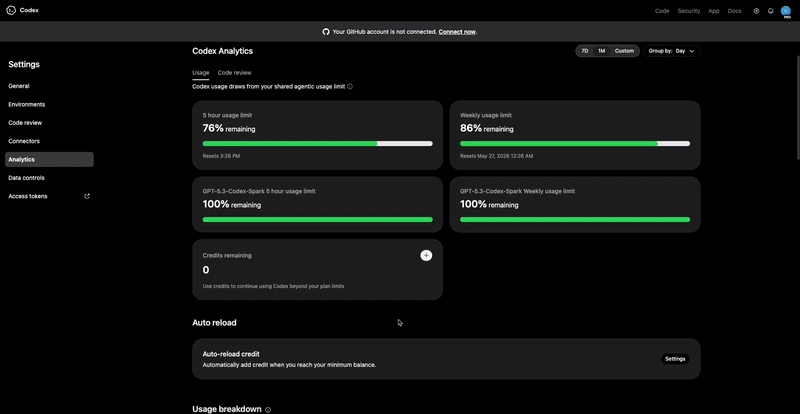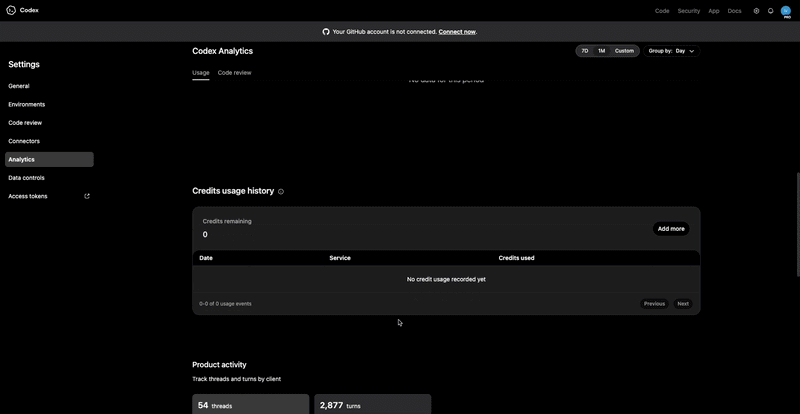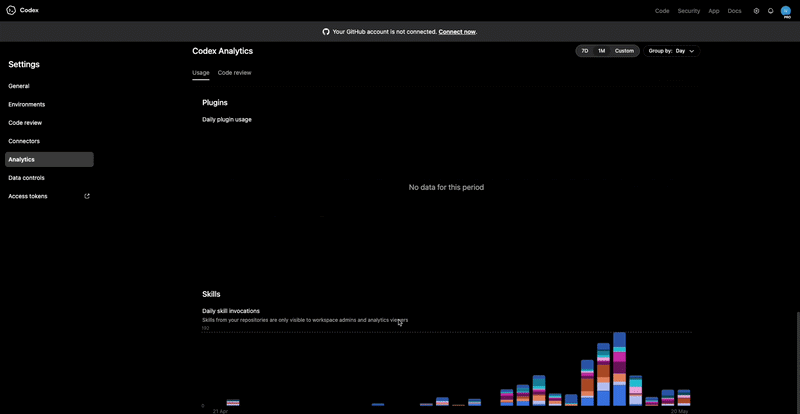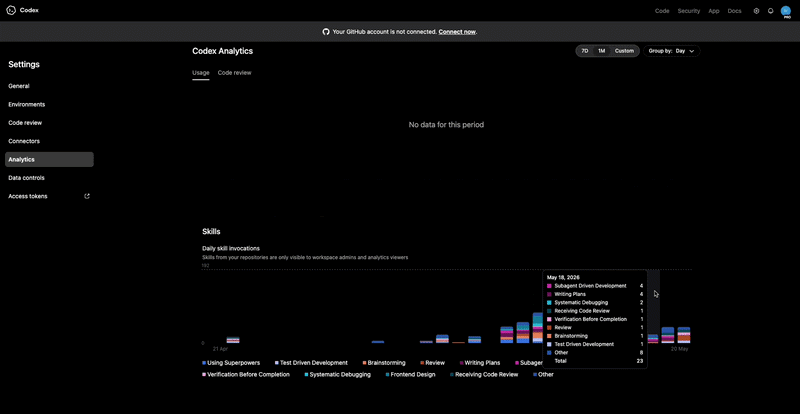
Why Token Tracking Alone Is Not Enough
Most tools still answer _“what did I spend today?” _Not “which repo, branch, feature, or session created the spend?”
That is the next wall.
Once AI spend crosses $200/month, attribution stops being optional. If you cannot explain where the spend went, you are operating blind.
The interesting question is not whether the providers can solve this. They can… They have local apps. Native dashboards. The infrastructure to ship a project → feature → session attribution layer next week if they wanted to!
**The question is whether they will. **They will not. Or at least, not soon.
Cross-provider attribution is not on any provider’s bucklist for the same reason cross-platform messaging was never on Apple’s bucklist.
A provider has every incentive to show you what you spent on them. They have zero incentive to show you the total bill across them, their competitors, and your half-abandoned branches.
That is the gap. The thing the providers will not build because it works against their own platform stickiness.
A unified umbrella that sits across Cursor, Claude Code, Codex, Gemini, Your CI agents, Your local scripts, Your random Tuesday-evening prototype
…and tells you what each feature actually cost you across all of them.
The category itself is the point. Solving cross-provider attribution under one umbrella is the problem worth solving, regardless of which tool wins…
I built VibeDeck for myself when I got tired of waiting. Local-first, macOS. Last month it told me 34% of my AI spend was unattributable to a specific branch or feature. Invisible at the rollup level every account-level tool ships with!
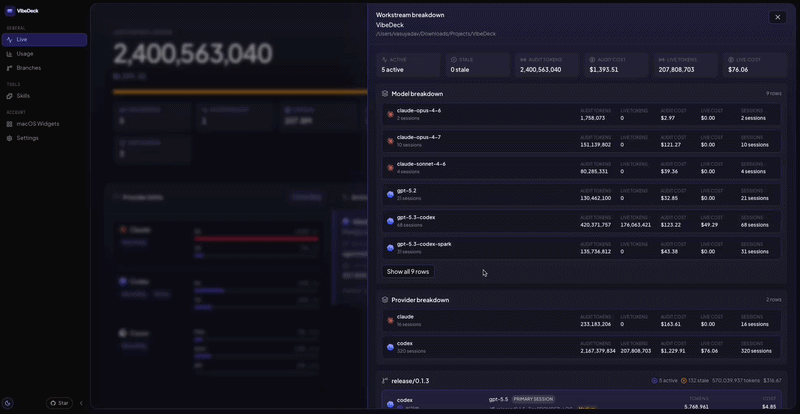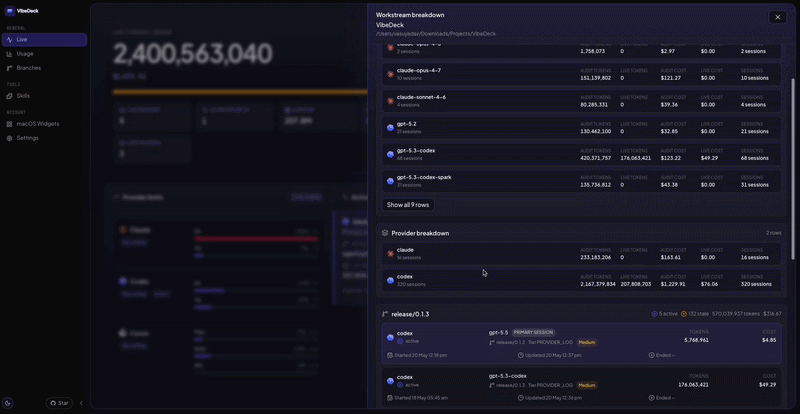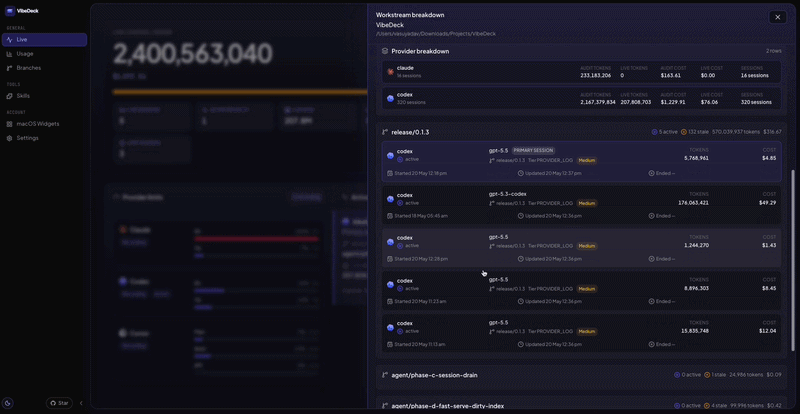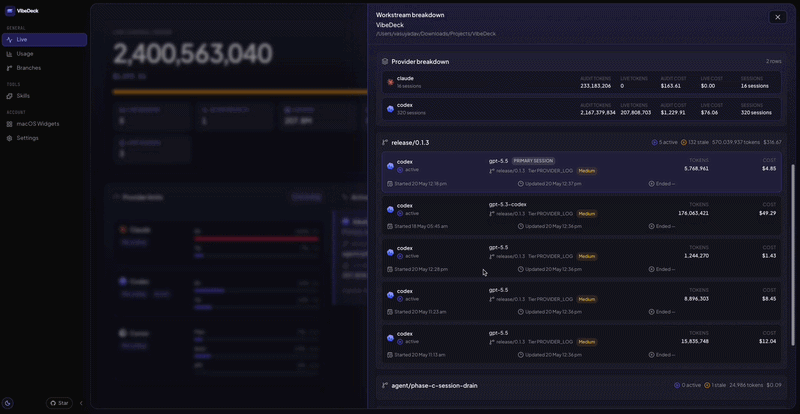
Other people are building other versions. The shape of the answer is what matters, not the logo on the menubar icon.
What This Means For Solo Developers
The lesson is not “agents are too expensive.”
The real lesson is uncontrolled agents are expensive. Scoped agents are useful.
You probably should not run 100 agents. You probably should not leave Fast Mode on all day. You probably should not let agents freely loop on vague tasks like “improve the app” or “make the codebase cleaner.”
A few well-scoped agents one for implementation, one for review, one for testing, one for research can absolutely make sense.
The key is discipline. Clear task boundaries. Standard mode by default. Usage caps. Branch-level tracking. Separate sessions per feature. A hard stop when the agent starts looping.
Without that, your AI workflow becomes a slot machine. You keep pulling the lever because sometimes it works. Then the bill lands.
What This Means For Startups
For startups the math is different…
A $3,000/month agent sounds expensive until you compare it with engineering payroll.
If one well-scoped agent can continuously review PRs, scan for security issues, catch regressions, monitor benchmarks, deduplicate issues, and prepare fixes, the math becomes interesting.
Not because the agent replaces a senior engineer. It does NOT!
But because it can absorb the repetitive review and monitoring work that engineering teams constantly postpone until it becomes painful.
That is real leverage. The problem is not whether agents are worth the money. The problem is whether you can prove where the money went.
If you cannot attribute spend to output, it becomes easy to cut. If you can show that $900 of AI spend reviewed 42 PRs, prevented 3 regressions, cleaned 120 duplicated issues, and created 11 usable fixes — that is a different conversation.
Now it is not just an AI bill. It is engineering capacity.
The Part Most People Will Miss
The headline is “Peter spent $1.3M on OpenAI.”
The real story is “we finally have a real data point for what continuous autonomous coding actually costs.”
It is not $20/month. It is not even $200/month. At serious scale, it is thousands per agent per month.
The market needed a number. For the last year, everyone has been selling agents like magic interns that cost less than lunch.
That was never going to hold.
Agents are not free labour. They are compute-heavy workers. And compute has a bill.
Three Takeaways To Leave With
First. Per-agent cost is not theoretical anymore. A serious always-on autonomous coding agent realistically costs between $3,000 and $13,000 per month depending on mode, workload, and how much freedom you give it.
Second. Both Anthropic and OpenAI are tightening session windows, weekly limits, and peak-hour throughput without raising sticker prices. Neither will acknowledge it openly. The $20 or $200 plan you have today is delivering less compute per month than it did at launch. And that trajectory continues.
Third. Attribution matters more than raw spend. The teams that win will not just ask “how much did we spend on AI?” They will ask “what did this feature cost us across every agent, provider, branch, and session?”
One Last Question
If you are using AI tools seriously, ask yourself one thing.
Can you look at last month’s AI spend and tell exactly which feature, branch, or piece of work created it?
If the answer is no your problem is not the model. It is not even the pricing.
It is visibility.
Steinberger gave the market a benchmark. The rest of us have to figure out what our own numbers actually mean.