Flagship models keep getting better, pricier, and usage-capped. The real advantage now comes from how intelligently you route planning, execution, and review across providers.
Every few months, the same cycle repeats.
A major lab releases a new flagship model. Benchmarks flood X/Reddit. People begin comparing scores, context windows, coding demos, and reasoning charts.
GPT 5.4 becomes GPT 5.5. Opus 4.6 becomes Opus 4.7. A few more features get added. Pricing changes. Usage limits shift.
And the market immediately jumps to the same question…
Which model is the best now?
After working with these systems continuously for months, that question feels increasingly outdated. Because the gap is no longer being created by the model itself.
The gap is being created by the workflow around the model.
Most flagship models today are already capable enough to produce high-quality output. What separates productive users from frustrated users is no longer access.
It is allocation.
Which task touches which model? Which provider handles heavy execution? Which provider handles review? How often expensive reasoning models are being wasted on repetitive work? How protected your workflow is from one company’s usage caps?
The Market Has Shifted From Capability to Monetization
Once the frontier models become broadly strong, providers stop competing only on intelligence and begin optimizing around packaging, premium tiers, and monetization.
The pricing trend over the last few releases makes that fairly obvious.
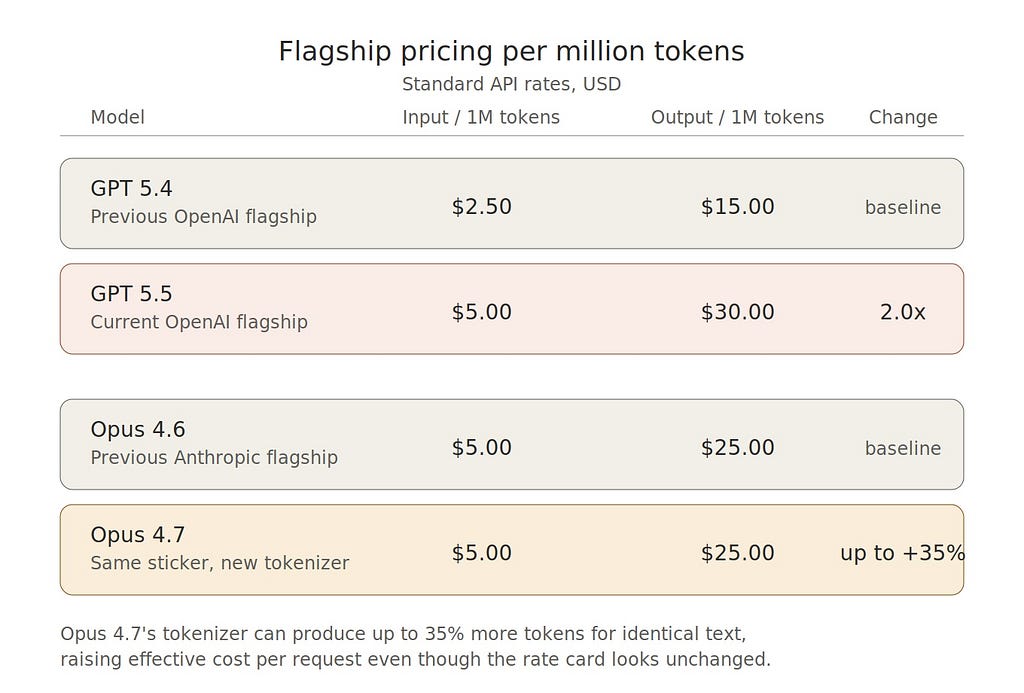
GPT 5.4 vs GPT 5.5
GPT 5.4 API pricing launched at • $2.50 per million input tokens • $15 per million output tokens
GPT 5.5 now sits at • $5 per million input tokens • $30 per million output tokens
That is effectively a 2x jump.
Yes, OpenAI positions GPT 5.5 as more autonomous and more efficient. But from a practical user standpoint, the direction is hard to miss:
the stronger the flagship gets, the more expensive it becomes to use as a universal worker.
Opus 4.6 vs Opus 4.7
Anthropic did not make the pricing sheet look dramatically different.
On paper, both continue around • $5 per million input tokens • $25 per million output tokens
But Opus 4.7’s stronger autonomous reasoning loops, longer coding chains, and heavier tool interaction have made it a noticeably more expensive daily worker in practical Claude Code sessions. Anthropic’s own release framing emphasizes longer independent task handling, which naturally means more burn over prolonged usage.
So while the price card may look stable, the real usage profile often is not. And that leads to the same conclusion.
Why Single-Provider Loyalty Is Becoming a Weak Strategy
They buy one premium subscription and assume that solves the problem:
Claude Max ChatGPT Pro One flagship ecosystem
The issue is not whether those plans are powerful.
THEY ARE!!!
In a market where all major providers already have capable models, tying your entire engineering output to one company’s plan is no longer the sharpest way to work.
A Good Workflow Is Not One Prompt — It Is a Structured Development Cycle
There is another mistake many users make once they get access to stronger models. They start treating AI coding as a one-shot execution machine.
integrate auth APIs build the billing UI change the project styling add notifications
and then they expect one long autonomous prompt to somehow produce clean engineering output.
That rarely works consistently. Because serious development work is not one blank execution task. It is usually a cycle.
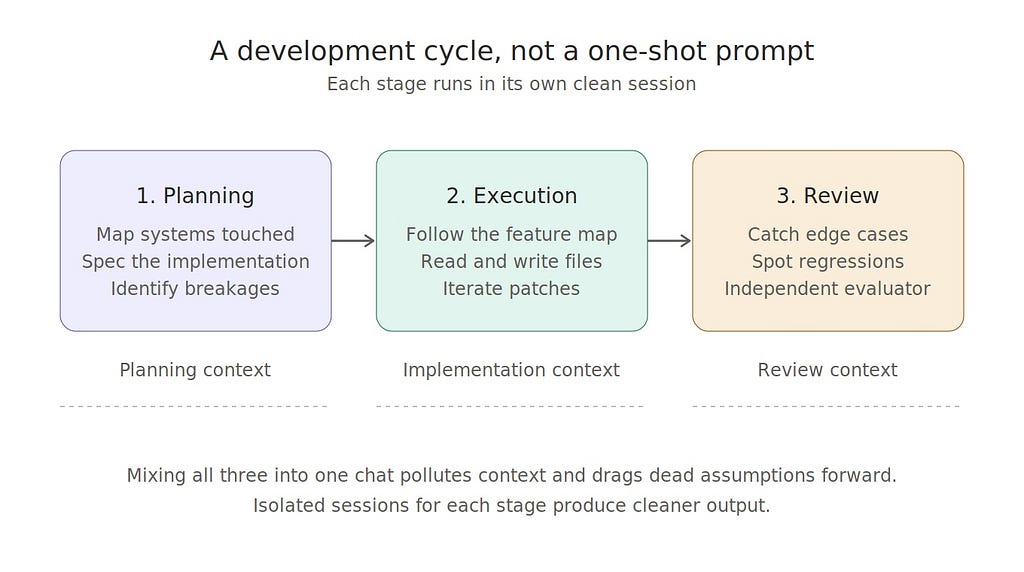
Planning Comes First
Before implementation, the feature needs shape.
What systems are changing? Which files are involved? What APIs are touched? Will current flows break? Does the UI change affect multiple components? Is there state management involved?
Even something as simple as “change styling across the app” is not a CSS task. It becomes layout consistency, component hierarchy, responsive behavior, and design debt.
Without planning, the agent starts coding with tunnel vision. You get movement… but not always coherence.
A broader feature view almost always leads to cleaner implementation.
Execution Comes Second
Once there is a proper plan, execution becomes far more stable. Now the coding agent is not inventing direction while editing files.
It is a feature map, a rough implementation spec, or at minimum a structured breakdown…. That reduces wasted loops dramatically.
Independent Review Comes Third
This part gets skipped more than it should. The same model that wrote the code is often asked to review the code.
That is not a real REVIEW
Because every writing agent carries its own assumptions. A separate reviewer catches what the first one normalizes.
Separate Sessions and Clean Context Matter More Than People Think
Another thing that improves output quietly is not mixing everything into one endless AI chat.
Planning should not live in the same context as raw implementation retries. Implementation should not share the same polluted state as the final code review.
Long mixed sessions drag too much irrelevant memory. Agents start carrying dead assumptions, old file states, and abandoned attempts.
Clean isolated sessions for planning, implementation, and review produce cleaner output than one giant chat trying to do all three.
This is where proper orchestration environments become useful. Not because they are trendy. Because they let each agent operate inside a more focused tree.
This Is Exactly Why Workflow Allocation Now Matters More Than Model Loyalty
Once tasks are separated properly, something becomes obvious. Not every stage deserves the same model. Using one premium reasoning model for every part of the pipeline is expensive and inefficient.
Planning, execution, and review all have different cost profiles.
Some need deeper reasoning. Some need repetitive file movement. Some need independent criticism.
This is where a distributed workflow starts outperforming a single premium subscription.
A Sharper $60 Workflow Can Quietly Beat a Flat $200 Subscription
A very practical stack: • Claude Pro — $20 • ChatGPT Plus — $20 • Cursor — $20
Total: $60/month
This is not about claiming these three plans are “better” than a $200 flagship plan in raw model power.
That is not the POINT…
The point is that this creates multiple execution paths instead of one expensive dependency.
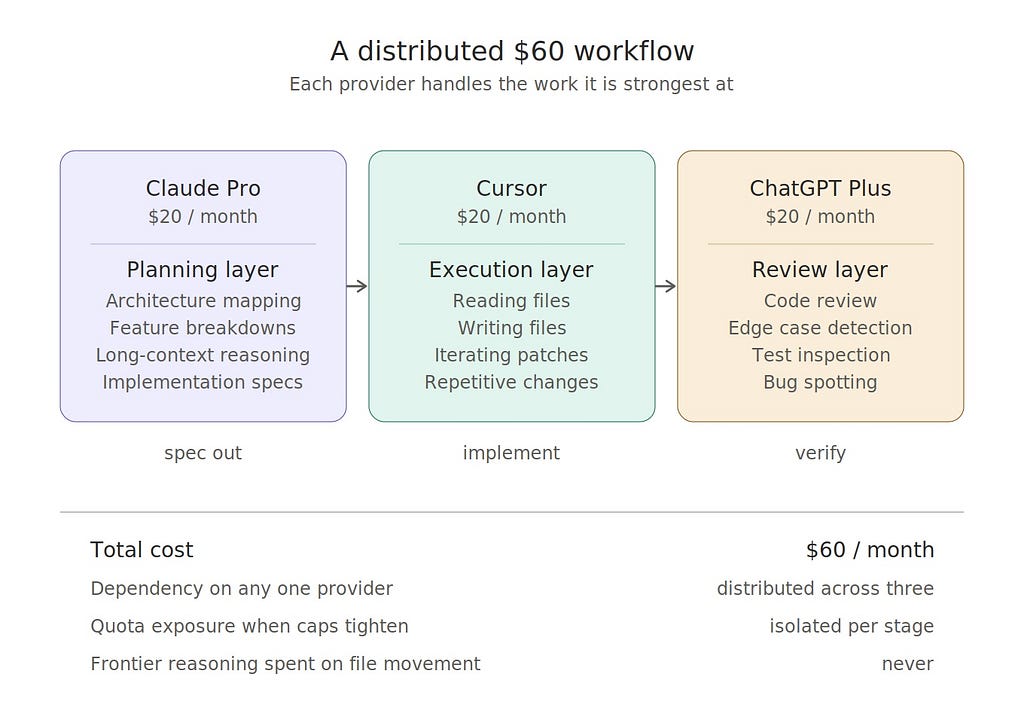
Claude as the Planning and Research Layer
Claude models still perform very strongly when used for: • brainstorming • architecture mapping • feature planning • long-context reasoning • implementation specs
This is where planning-oriented skills become extremely useful. One that has worked consistently for me is Superpower.
It is particularly strong at: • brainstorming implementation routes • writing structured feature plans • identifying touched systems • converting broad goals into executable subtasks
That changes the workflow from “build this feature” to “think through this feature first, then distribute the work.”
That difference saves far more usage than people realize.
Cursor as the Bulk Execution Layer
Most usage in any coding workflow does not actually go into reasoning.
It goes into reading files, writing files, iterating patches, and making repeated changes.
This is repetitive implementation labor. That is exactly where Cursor becomes useful. Let the execution-heavy work happen there instead of wasting expensive frontier reasoning models on raw file movement.
Codex as the Independent Review Layer
Once implementation is done, a second evaluator becomes valuable.
GPT 5.x / Codex class models are very effective for: • code review • alternate implementation suggestions • test case inspection • edge-case detection • bug spotting
The point is not that they must always be the reviewer.
The point is that the writer should not be the only judge of what was written.
This Is Not About One Specific Tool — It Is About Building an AI Engineering Team
The exact TOOLING can vary…
Some people may use different providers. Some may use different orchestration environments. Some may use different planning skills.
That is secondary.
The underlying shift is the same: serious users are no longer using one AI assistant. They are building coordinated AI workflows.
And that mindset changes the economics completely.
This Does Not Become Efficient on Day One
A distributed workflow takes tuning.
You need to learn which tasks deserve deeper planning, where execution agents start drifting, when a secondary reviewer is actually useful, and how much context each provider should receive.
But that is exactly how every serious engineering system works. No productive system is immediately efficient. It becomes efficient because it is tuned.
Where This Market Is Actually Heading
The smartest users are no longer asking, “Which flagship model provider should I be loyal to?”
They are asking, “How do I build the most cost-efficient high-output workflow across all capable providers available to me?”
That is a much more durable question. Because new models will continue arriving. Pricing will continue shifting. Premium plans will continue getting repackaged. Usage caps will continue changing.
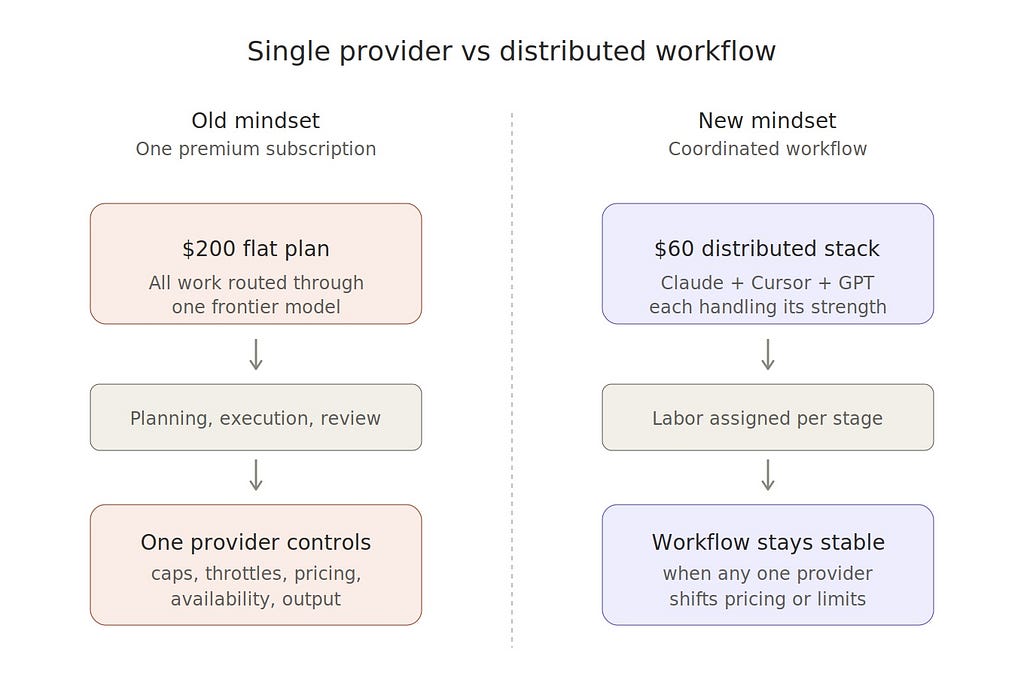
Provider behavior will always move… Your workflow can remain stable….
Conclusion
The era where simply buying the newest flagship plan gave you the largest advantage is fading…
Model quality is no longer scarce!!!
Efficient orchestration is. And that means the real edge is moving away from provider loyalty and toward workflow design.
The users who will get the most out of AI over the next year will not necessarily be the ones paying for the most expensive subscriptions.
They will be the ones who learn how to make multiple capable systems work together with precision.