There is a new primitive in agentic coding. It goes by different names depending on which provider you are using. In Codex and Claude Code it is /goal. In Cursor, it is closer to Background Agents combined with /best-of-n and the new Agent Window orchestration.
Strip the branding away and the primitive is straightforward.
You define an outcome. The agent works toward that outcome across multiple turns, evaluating its own progress against evidence, until either the outcome is met, the budget is exhausted, or you pause it.
That is it. That is the whole pattern.
But the architecture underneath determines whether the pattern actually works on a real codebase, or whether it burns half your session limit producing changes that look fine on the surface but quietly damage your release branch.
I have spent the last two weeks running goals across all three providers. One of them I ran for 15 hours straight on a real performance-optimization project. What happened during those 15 hours is the most useful thing I can tell you about this primitive, but only after we go through the architecture, because the architecture explains everything that happened.
Let me show you the moving parts first. The story comes after.
What A Goal Actually Is?
A traditional prompt is a single-turn exchange. You ask… The agent works… The agent stops!!! You wait… You ask AGAIN…
A goal converts that into a continuation loop.
The agent works → checks the evidence → decides whether the outcome is met → continues if not…
It is the same difference as the gap between a function call and a state machine. One terminates after one execution. The other terminates only when a condition is satisfied.
The OpenAI cookbook on Goals, describes the architecture pattern with unusual precision:
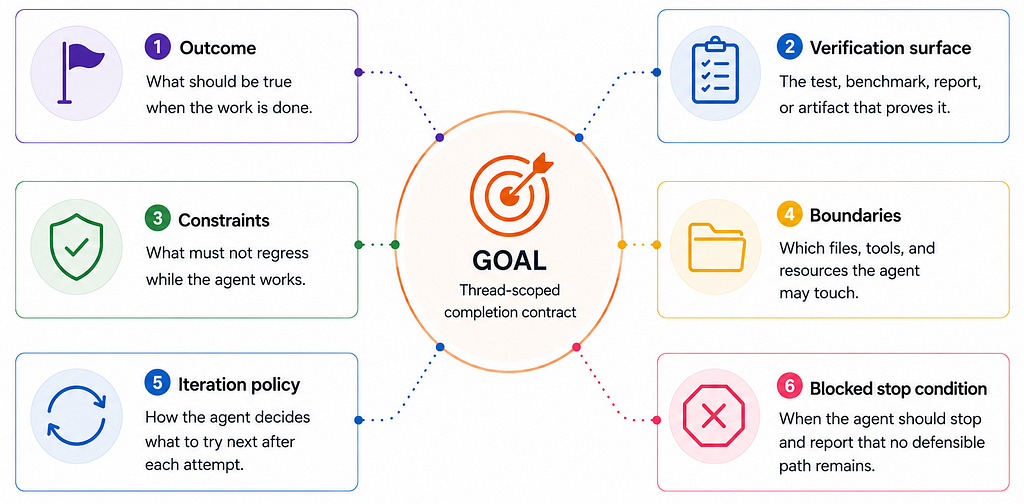
“A Goal is a thread-scoped completion contract. It combines durable objective state, lifecycle controls, continuation policy, budget accounting, and evidence-based completion.”
Six components. Skip any one of them and you do not have a goal, you have an agent in a while True loop.
The six pieces:
- Outcome — what should be true when the work is done
- Verification surface — the test, benchmark, report, or artifact that proves it
- Constraints — what must not regress while the agent works
- Boundaries — which files, tools, and resources the agent may touch
- Iteration policy — how the agent decides what to try next after each attempt
- Blocked stop condition — when the agent should stop and report that no defensible path remains
Codex calls this a completion contract. Claude Code calls it a completion condition. Cursor calls it a task description with a verification surface. They are all describing the SAME thing.
The interesting question is what each provider does with that contract once you hand it over.
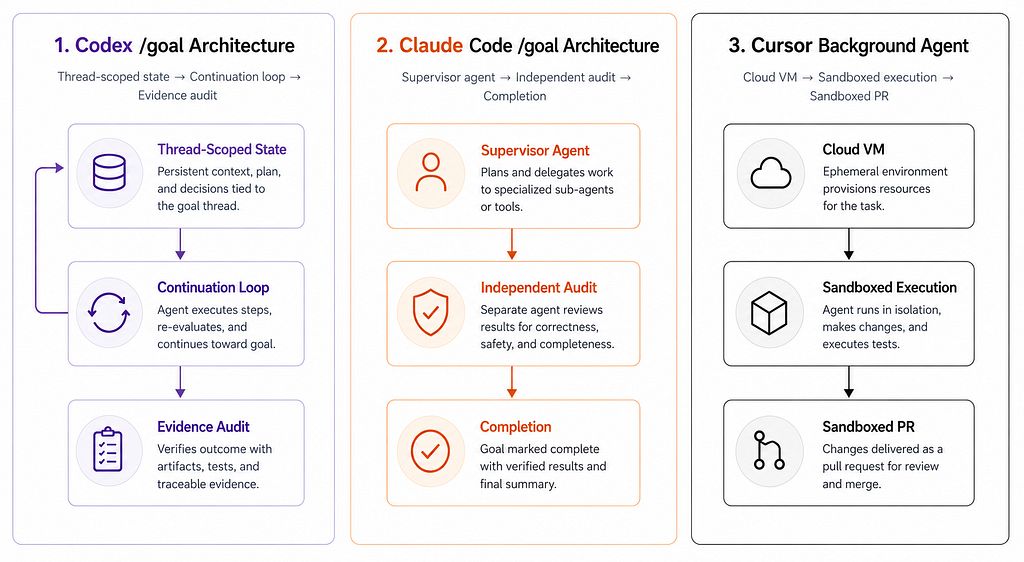
Codex: The Most Architecturally Explicit Implementation
OpenAI shipped Goals in Codex 0.128.0. And the cookbook documentation that landed with it is and I do not say this lightly, one of the clearest architecture writeups any AI lab has published this year.
Three things worth understanding about how Codex implements /goal:
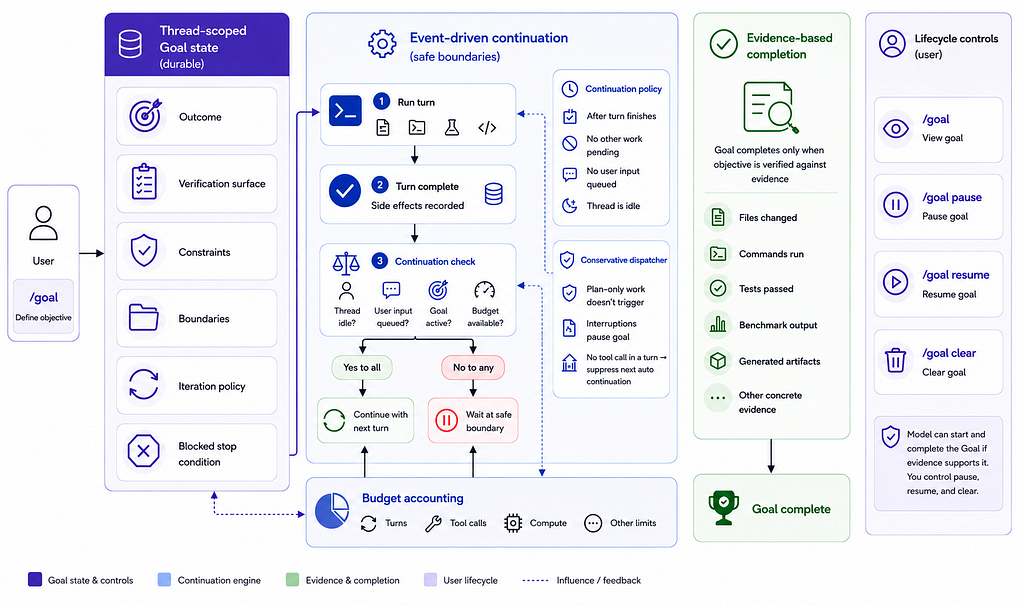
1. Thread-scoped state, not global memory.
The Goal lives in the thread where you defined it. Not in AGENTS.md. Not in your global Codex config. Not in some account-level memory store. The objective belongs to the thread that has the relevant context — the files Codex inspected, the commands it ran, the diffs it produced, the reasoning trail it built.
This is more important than it sounds.
A Goal in Codex is not a permanent instruction. It is a persistent contract attached to one specific conversation.
You can PAUSE it. You can RESUME it. You can CLEAR it. You can let it COMPLETE. But it never leaks across threads, which is exactly the right design because the context of one feature should not bleed into another feature.
2. Continuation is event-driven, not a while True loop.
This is the part people get wrong when they imagine how /goal works. The agent does not keep generating tokens until the objective is met. That would burn through quota in minutes.
Instead, Codex waits at safe boundaries.
“Codex checks for continuation only at safe boundaries: after a turn has finished, when no other work is pending, when no user input is queued, and when the thread is idle.”
So the loop is:
- Codex runs a turn
- Turn completes (writes a file, runs a test, etc.)
- Codex checks: is the thread idle? Is user input queued? Is the Goal active and within budget?
- If yes to all three → continue with the next turn
- If no → wait
The dispatcher is deliberately conservative. Plan-only work does not trigger continuation. Interruptions pause the objective. If a continuation turn makes no tool call, the next automatic continuation is suppressed so Codex does not spin. This is the engineering detail that prevents /goal from becoming a quota disaster on its own.
3. Completion is evidence-based, not model-confidence-based.
A Goal in Codex does not complete because the model thinks it is done. It completes only after the objective is checked against:
- Files changed
- Commands run
- Tests passed
- Benchmark output
- Generated artifacts
- Other concrete evidence
This is the most important architectural choice in the entire design. The model can lie to you about completion. The evidence cannot. Codex enforces that the model has to point at something real before it can mark a Goal complete.
The four lifecycle commands are:
/goal — view the current Goal
/goal pause — pause an active Goal
/goal resume — resume a paused Goal
/goal clear — remove the current GoalThe model can start a Goal and mark it complete if the evidence supports completion. Pausing, resuming, and clearing remain in your hands. That asymmetry is intentional. The model is allowed to be productive. It is not allowed to be its own judge of when to stop being productive.
Claude Code: The Orchestrator Architecture
Anthropic shipped /goal in Claude Code three days after the OpenAI cookbook dropped. Same primitive name. Different implementation.
The biggest architectural difference is what Anthropic calls the independent audit.
When Claude Code reaches what it thinks is the completion state, it does not mark the Goal complete on its own.
“A second, independent Claude session reviews the final repository state to confirm the goal was actually achieved before notifying the user.”
Two agents, not one.
The implementer agent does the work. A separate auditor agent — running in a clean context with no memory of the implementation reasoning, looks at the final state and decides whether the Goal was actually met.
This is a fundamentally different completion model from Codex. Codex says “the evidence has to support completion.” Claude Code says “a second agent has to agree the evidence supports completion.” Both work. Both have tradeoffs.
The Claude Code surface ships across three execution contexts:
- Interactive mode — TUI conversation, run /goal directly
- -p flag — non-interactive scripting, similar to codex exec
- Remote Control — Claude Code’s cloud execution model
The system tracks elapsed time, turns, and tokens during the run. Early reports — via @AlexFinn, @dani_avila7, @milesdeutscher on X — describe Goals running for hours or even days on complex objectives.
The other notable difference: Claude Code requires auto mode for long-running Goals and works as a classifier between —dangerously-skip-permissions and per-call approvals. The classifier reviews each tool call before execution and blocks anything that looks like mass deletions, data exfiltration, or malicious shell.
You enable it with shift + tab in CLI, or via the mode selector on desktop. Without it, every tool call would queue an approval prompt and the Goal cannot make progress while you sleep.
Cursor: Background Agents As The Approximation
Cursor does not call its equivalent /goal. The closest primitive is Background Agents, expanded heavily in Cursor 3 and refined further in Cursor 3.2
The architecture is different again. Cursor’s approach:
1. Cloud VM execution.
A Background Agent does not run on your laptop. It runs in a sandboxed cloud VM, picks up GitHub issues, opens draft PRs, responds to Slack messages, and runs scheduled tasks. Your machine can be off. The Goal continues.
2. Tool-call budgets instead of evidence audits.
Where Codex insists on evidence-based completion and Claude Code uses a second-agent audit, Cursor caps Background Agents at 25 tool calls (200 in Max mode). Hit the cap and the agent stops. This is a simpler but blunter completion model — it stops when it has done enough work, not when it has produced enough evidence.
3. Worktrees as first-class isolation.
Cursor 3.2 added worktrees for agents — each task runs in its own isolated branch and merges back when ready. This is the same pattern that has been the right answer to “multi-agent isolation” since Git 2.5, and Cursor is the first commercial provider to make it the default.
4. /best-of-n as the parallelism primitive.
The other thing Cursor 3 shipped is /best-of-n — same task, multiple models, parallel worktrees, you pick the winner. This is closer to a Goal-with-fallback-strategies than to a single Goal, but in practice it serves the same purpose. You define an outcome. The system tries multiple paths. You evaluate which succeeded.
Cursor’s launch from cursor.com/agents, mobile, Slack, GitHub, and Linear means the entry surface is much wider than Codex or Claude Code.
Three Implementations, One Comparison Table
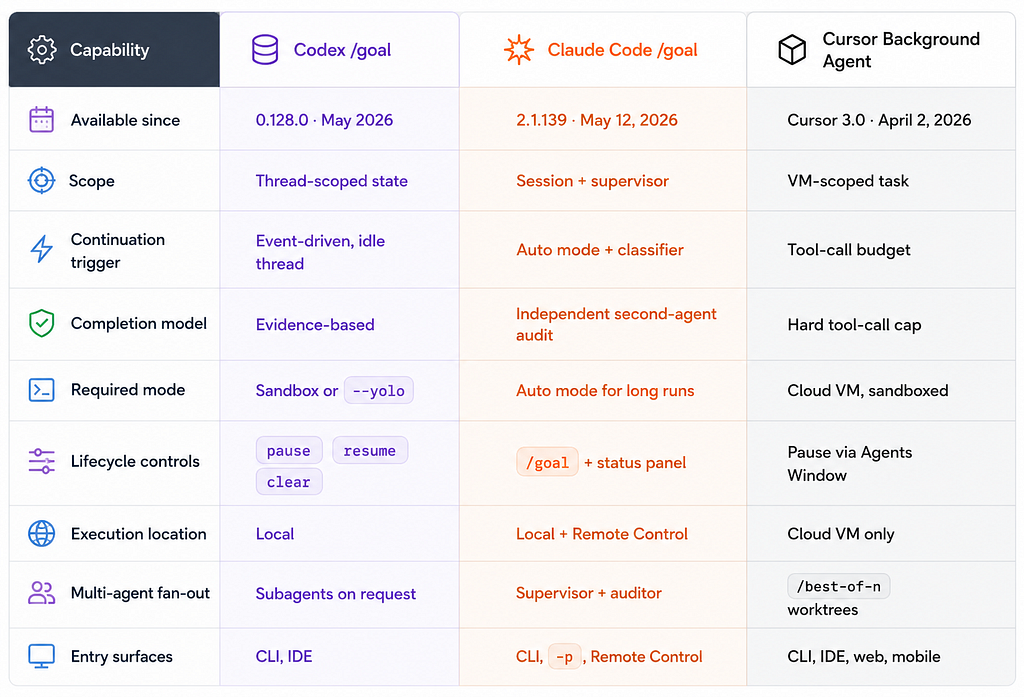
The biggest practical takeaway from this table:
Codex gives you the most explicit architecture. Claude Code gives you the strongest completion guarantee. Cursor gives you the widest entry surface.
Pick based on which one matches your actual workflow. If you work in the terminal and care about quota efficiency — Codex.
If you delegate work and want a second agent checking the first — Claude Code.
If you want to fire off a goal from your phone on a Sunday evening — Cursor.
Can /goal Only Run In YOLO Mode? Or Also In Sandbox?
Short answer: both. With caveats.
In Codex, Goals run in any sandbox mode, but the practical reality is that long-running Goals are crippled by per-call approval prompts. The four modes:
read-only — Goal can think, cannot act → useful for research goals
workspace-write — Goal can modify project files → standard for code work
danger-full-access — Goal can run anything → matches --yolo
--yolo — Alias for danger-full-access, no approvalsIf you launch a Goal in workspace-write with —ask-for-approval on-request, the Goal pauses every time it wants to run a non-allowlisted shell command. For a 15-hour run, that means 15 hours of you being needed to click “allow” every few minutes.

The pragmatic configurations:
- —sandbox workspace-write —ask-for-approval never — file modifications without approvals, shell commands blocked unless whitelisted. Good middle ground.
- —full-auto — preset that combines workspace-write and never-prompt. The standard for codex exec in CI.
- —yolo — full access, no approvals. The mode you use only when you have branch-level isolation and a real plan to limit blast radius.
Same principle for Claude Code. The /goal command works at any permission level but auto mode is what makes long-running Goals actually viable. Without it, you get an approval prompt blocking every meaningful action.

Cursor’s Background Agents sidestep this entirely — they run in a fresh sandboxed VM, so the permission question reduces to “what can the VM reach” rather than “should this command run.” Different model, different tradeoff.
The goal.md File And Why You Need One
Both Codex and Claude Code support reading Goals from a file rather than typing them inline at the command. The convention is goal.md (or goals/<feature>.md) checked into the repo.
A good goal.md:
# Goal: Reduce p95 latency below 120ms
## Outcome
p95 latency on the checkout benchmark below 120ms,
verified by the benchmark output.
## Verification surface
- `pnpm bench:checkout` must report p95 below 120ms
- Correctness test suite (`pnpm test`) must stay green
- No new dependencies added
## Constraints
- Do not modify public API contracts
- Do not change DB schema
- Do not regress any of the 14 correctness tests
## Boundaries
- Allowed paths: services/checkout/**, tests/checkout/**
- Forbidden paths: shared/, billing/, db/migrations/
## Iteration policy
After each change, run the benchmark, log the result,
and choose the next experiment based on what the
benchmark output shows. Record every attempt with
the diff, the benchmark delta, and what you would try next.
## Blocked stop condition
If the benchmark cannot run, or three consecutive
experiments produce no improvement, stop. Report the
attempted paths, evidence gathered, and the next
input you would need from me to unblock.That structure is not optional. The Goal will inherit the gaps in your goal.md. Underspecified outcomes produce wandering agents. Vague iteration policies produce slot-machine behavior. Missing stop conditions produce $400 invoices.
The Audit Skill You Need Before You Use /goal
If you take one thing from this post, take this.
Running /goal without an audit skill is asking for trouble.
When a Goal runs autonomously, there is no human in the loop. Each agent in the chain — implementer, reviewer, auditor — naturally drifts toward agreeing with the previous step. This is a known failure mode of multi-agent systems. The reviewer wants to be helpful. The auditor wants to be efficient. Both end up rubber-stamping the implementer’s work.
The fix is what I call evidence-driven audit — a skill the auditor agent loads that forces it to:
- Read the actual changed files with its own tools, not just summarize the implementer’s report
- Run the verification commands locally and quote the actual output, not the implementer’s claim about the output
- Diff against the merge base and flag anything outside the stated boundaries
- Refuse to agree with a previous agent’s conclusion unless it can independently verify the claim
The Claude Code supervisor architecture has a version of this built in (the independent second-agent audit). Codex does not — you have to bring your own auditor. If you are using Codex /goal for anything beyond a toy task, write an audit skill first.
A minimal skill template:
---
name: evidence-driven-audit
description: |
Use after any /goal completes or pauses. Verifies that
claimed changes were actually made and produced the
claimed evidence. Does not trust the implementer's
summary — re-reads files and re-runs commands locally.
---
# Evidence-Driven Audit
When invoked:
1. Read the current diff against the merge base.
Quote the actual hunks, not the implementer's summary.
2. For every claim in the implementer's notes, find the
evidence:
- "Tests pass" → run the tests, quote the output
- "Benchmark improved" → run the benchmark, quote the output
- "No regressions" → run the regression suite, list any failures
3. Check boundary adherence. List every file changed.
Cross-reference against the boundaries defined in goal.md.
Flag any out-of-scope changes.
4. Refuse to agree with prior agents unless independently
verifiable. If a claim cannot be verified, mark it
"unverifiable" and explain what evidence would be needed.
5. Output a structured audit report:
- Verified claims (with evidence quoted)
- Boundary violations (with file paths)
- Unverifiable claims (with required evidence)
- Recommended action: merge / revise / abandonThis skill is the safety net under the entire /goal workflow.
What Happened When I Ran A Goal For 15 Hours
This is the part of the post where I stop reciting architecture and tell you what actually happened.
The setup. I had a project that needed performance optimization. The phase plan was already in place — I had broken the work into discrete phases, each with its own worktree separate from the release branch. Stress tests after each phase, on my machine. The AGENTS.md for the project specified:
- 5.5 xhigh as the orchestrator
- 5.5 xhigh as the implementer
- 5.5 xhigh as the auditor
- 5.4 high as the reviewer
I started /goal with what I thought was a tight contract — finish the phase plan, run the stress tests, and “if you find any gaps between phases after the stress testing, IMPROVE THOSE TOO.”
That sentence is what ran for 15 hours.
The orchestrator hit the end of the planned phases in roughly the first 8 hours. Then it kept going, because my “improve any gaps” instruction was open-ended enough that the agent interpreted it as license to keep finding new things to improve. It found gaps. It improved them. It stress-tested. It found new gaps that the improvements introduced. It improved those too.
I was on a $100 Codex Pro plan. My usage went from 100% available at the start of the run to 72% available by the time I paused it. That is 28 percentage points of my weekly usage consumed in a single overnight run.
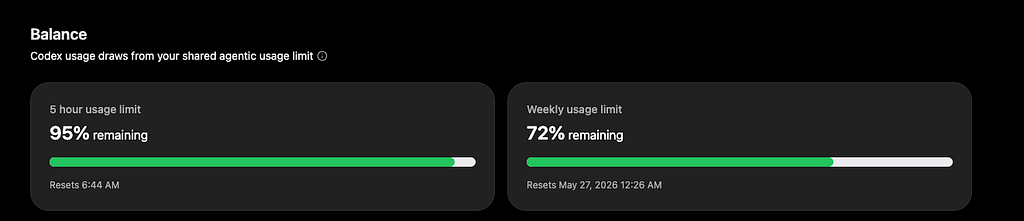
I paused it using /goal pause.
At first, I was honestly skeptical. The model had been completely autonomous with no human in the loop for over half a day. The changes were sprawling. I did not know what to trust.
So I ran my evidence-driven audit skill on the last merged branch. And it passed. Why would it not? I had been using the highest-tier models throughout the chain. The audit verified that the changes were real, the boundaries had held, and the stress tests genuinely improved.
After brainstorming with the agent on the final spec — adding a few things I had thought of during the audit — the work was actually mergeable.
Would I do it again?
Maybe. Maybe NOT. Here is the honest tradeoff.
What worked:
- Phase plan was already in place before /goal started. The agent had structure to extend, not invent.
- Every phase had its own worktree. Blast radius was contained to throwaway branches. If nothing worked, I had only wasted tokens, not corrupted the release branch.
- The audit skill caught two boundary violations that I would have missed in a manual review.
- I did not spend a day reverse-engineering an agent mess.
What did not work:
- The cost overhead was a complete nuisance. 28 percentage points of weekly quota for one feature improvement is not sustainable.
- The “improve any gaps” framing was too open-ended. In a normal feature release, you have specific improvements with specific boundaries. My /goal did not.
- The agent kept finding things to improve because I left the door open. That is on me, not the model.
The honest takeaway is what I would have told myself before starting:
Direct /goal with no flow or plan would do more damage than good. /goal with a phase plan, worktree isolation, and an audit skill is workable but expensive. Use it deliberately, not casually.
When To Use /goal (And When Not To)
“Do not use a Goal for a one-line edit, a simple explanation, a short code review, or a question where you want one answer and then a stop. A normal prompt is better for that. Do not use a Goal when the finish line is vague.”
When /goal actually earns its place:
- Performance optimization with measurable benchmarks (latency, throughput, memory)
- Flaky test investigation where reproduction is the bottleneck
- Dependency migrations with deterministic completion criteria
- Bug hunts that require iterative reproduction
- Multi-step refactors where the path is uncertain but the end state is testable
- Test-driven refactoring where the test suite is the verification surface
- Documentation completeness audits where the artifact is the spec
When /goal is the wrong tool:
- One-line edits. Use a normal prompt.
- Vague objectives. “Make this better” is not a Goal. It is a slot machine.
- Tasks where you want to review each change. Goals run autonomously. If you want gates, use a normal session.
- Anything where the cost of error exceeds the cost of the alternative. Production hotfixes are not Goal-shaped.
The pattern across all of these is the same: the finish line must be measurable. If you cannot define what “done” looks like in a way the agent can verify, you do not have a Goal. You have a WISH
What This Story Is Really About
I want to land this on the broader pattern because /goal is one piece of a larger shift.
The agentic coding ecosystem in 2026 is moving from prompt-driven work to outcome-driven work. The vendor announcements all rhyme. Codex shipped Goals. Claude Code shipped /goal and auto mode. Cursor shipped Background Agents and Agent Window orchestration. All three providers are betting that the future of AI-assisted coding is “define an outcome, walk away, come back to evidence.”
That is a different shape of relationship with the tool. Synchronous prompting is exhausting. You sit. You read. You prompt. You sit again. Outcome-driven async work is the way out of the always-on-keyboard treadmill.
But the architecture matters more than the marketing. The labs that get this right will be the ones with proper evidence audits, sane budget accounting, and conservative continuation dispatchers. The labs that get it wrong will hand you a $800 invoice and three pull requests that look fine until they are merged.
Codex’s design is the most explicit about the contract evidence-based completion, event-driven continuation, thread-scoped state. Claude Code’s supervisor architecture is the most defensive about model self-deception — two agents have to agree before completion is declared. Cursor’s cloud-VM model is the most accessible — start a Goal from a phone in 2026 and find a PR waiting in the morning.
Use the one that matches your workflow. Bring your own audit skill regardless of which one you pick. And do not run a Goal without phase planning and worktree isolation unless you genuinely enjoy the smell of burnt tokens at 3 AM.
A Genuine Question
For anyone who has actually run a Goal end-to-end across one of these three providers — how long did your longest run go, what was the outcome, and what was the cost in quota or tokens?
Tell me what actually happened.
If you have a goal.md template you have iterated on across multiple runs, share it. If you have an audit skill that has caught something the implementer claimed it had not done, share that. The shape of the answer to “is /goal worth it?” is being formed right now in private conversations between people who actually ran it. Let’s drag some of it into the open.
The architecture is well-documented. The empirical data is not. I would rather read your 15-hour-run story than another “how to write a Goal” tutorial.