How demand spikes, common dependencies, and model-level instability slowly revealed larger fractures.
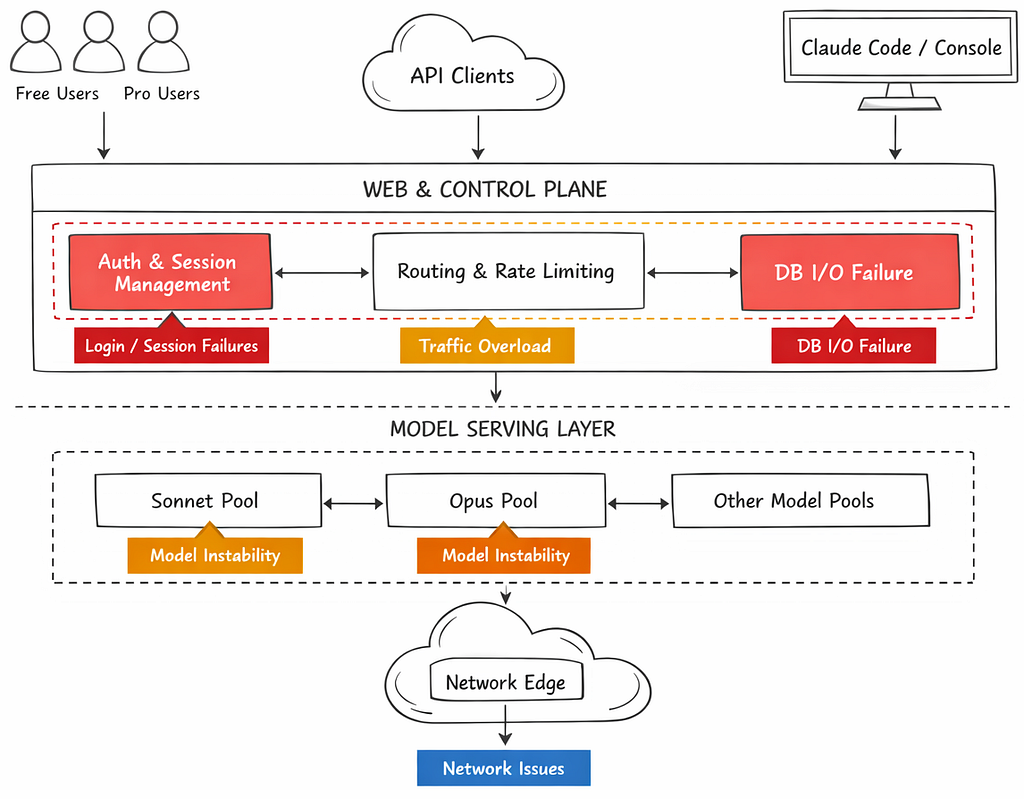
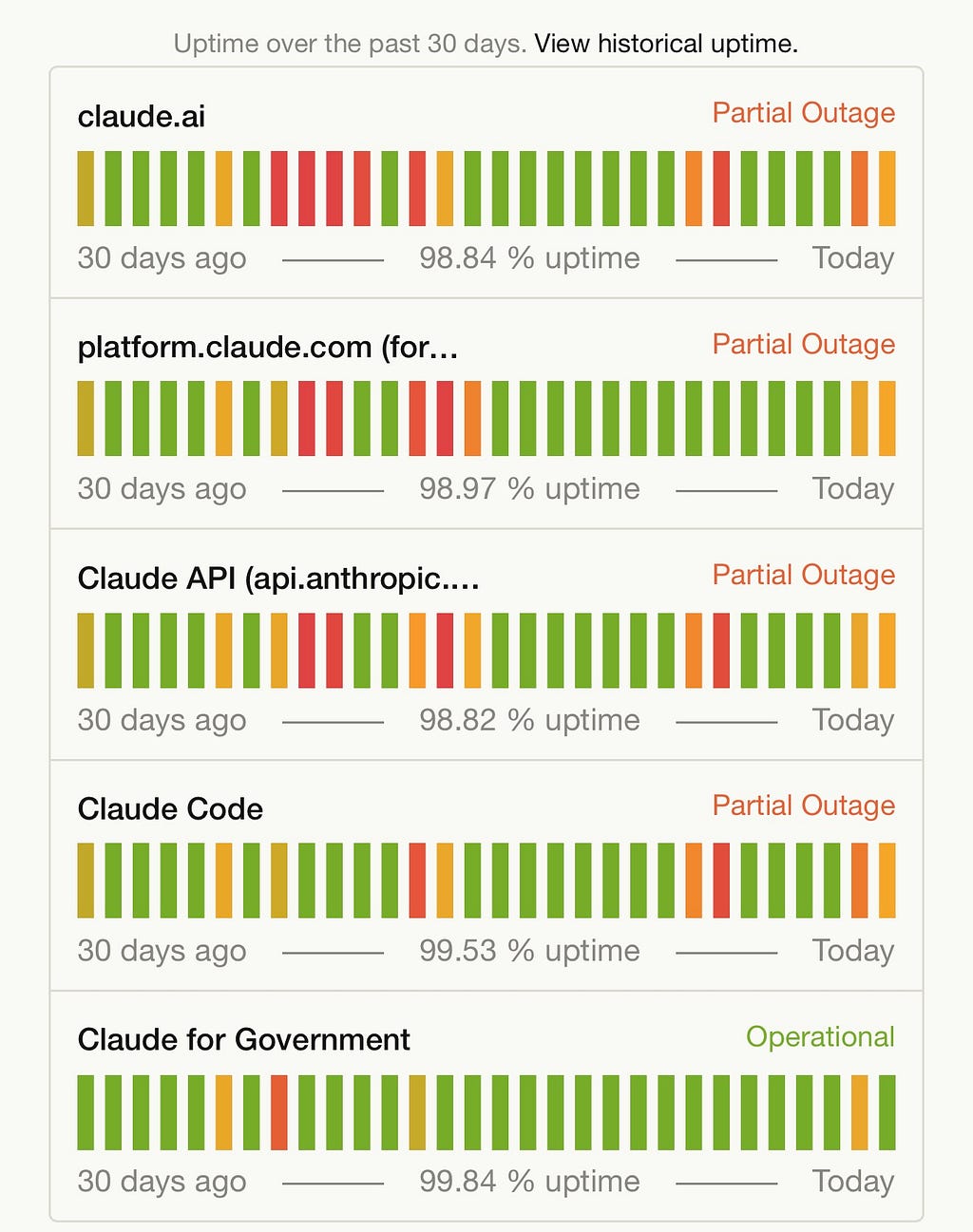
Most people talk about the March Claude outage as if it were a single, model episode.
It was not.
What actually occurred was a series of failures, each affecting a separate component of the system. When you look at them together, they begin to create a much more compelling story.
March 2: Control Plane Due to Demand Surge
The first major signal appeared when Claude experienced a surge in usage after briefly becoming #1 on the Apple App Store.
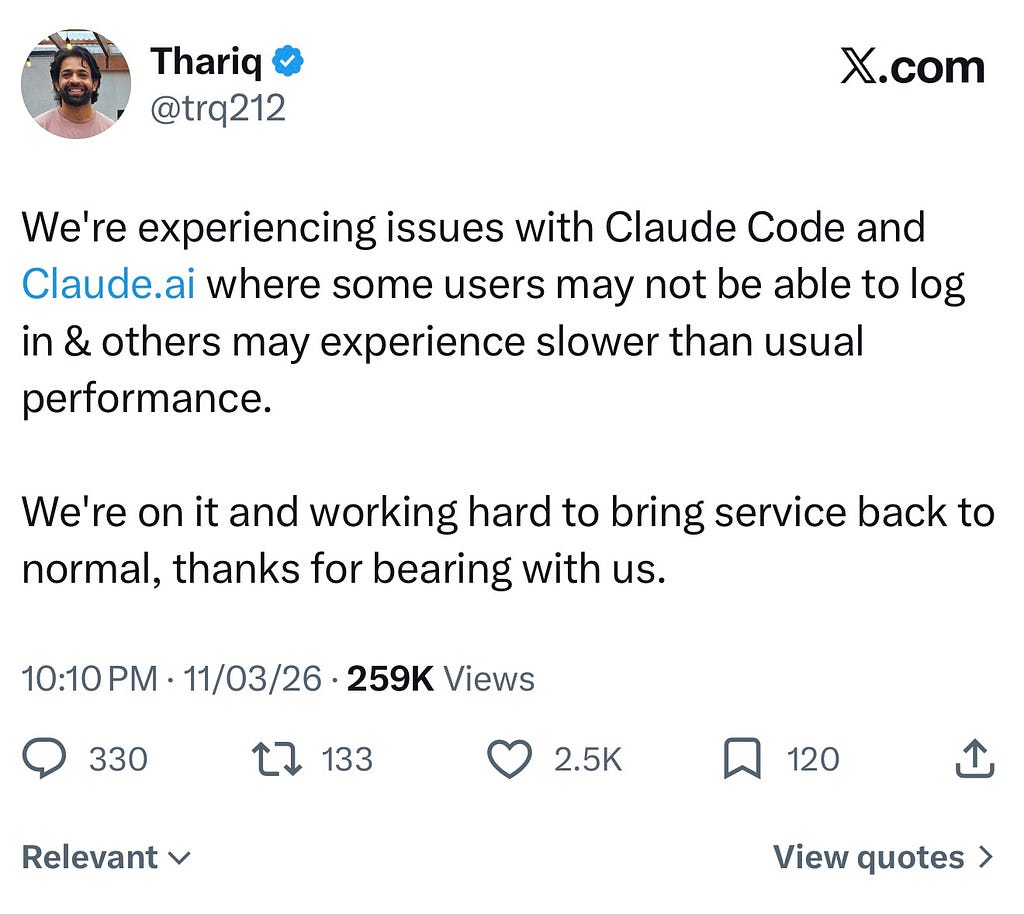
But the system didn’t break where most people expected. It didn’t fail at the model. It failed at the entry point.
Users had problems with: • Log in properly • Refresh sessions • Route requests

At the same time, a lot of API users were still working fine.
It suggests the inference layer was not the immediate bottleneck.
Instead, the issue was concentrated in the control plane the systems responsible for authentication, request routing, and user session management.
Observation: Prior to the core system failing, the front door failed.
March 11: Shared State Dependency Failure
There was a second, more tangible failure.
After routine maintenance, Anthropic’s own postmortem revealed a primary application database with deteriorated I/O.
The impact: • Claude’s performance drastically declined • Sign-in and session refresh failed • Claude Code and Console were affected • API remained largely operational
This highlights a well-known architectural problem: A single shared dependency with high blast radius.
When the database slowed down, every system depending on it, particularly authentication and app state was affected simultaneously.
Observation: Control-plane dependencies were too centralized and insufficiently isolated.
March 16–18: Model-Specific Instability and Tier Leakage
This is where things got more interesting.
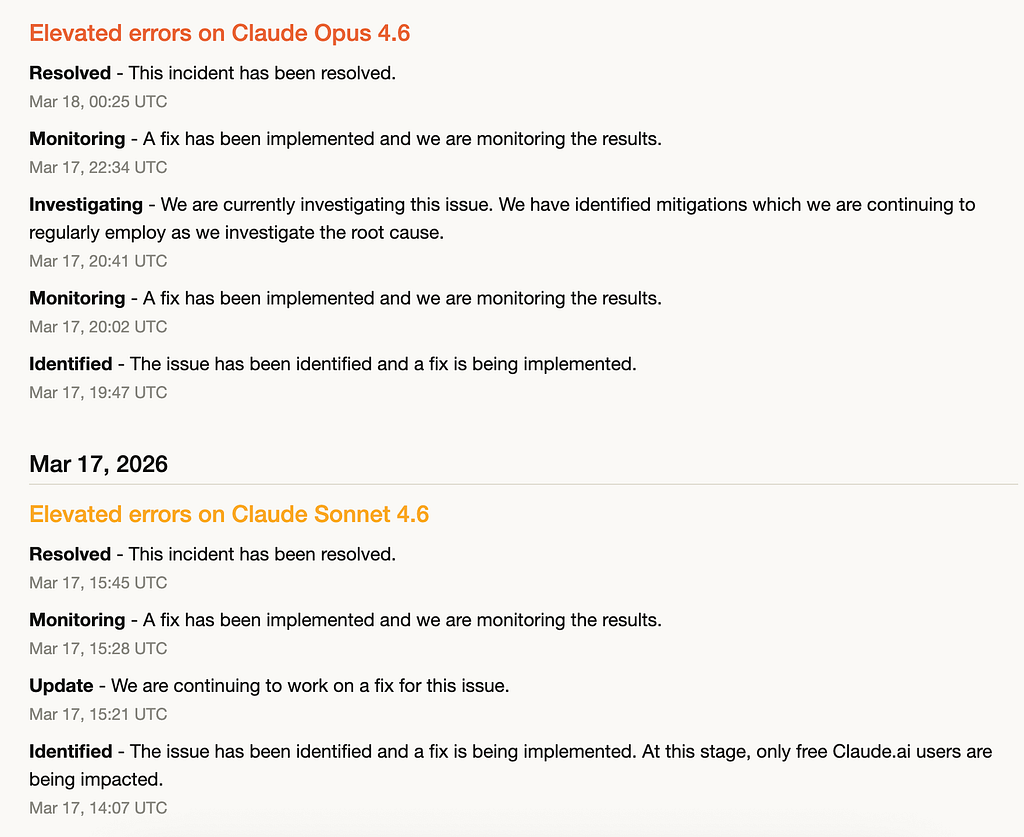
During March 16–18, incidents began to cluster around Sonnet 4.6 and Opus 4.6.
The failure pattern was inconsistent: • Some incidents affected only free users • Others extended to API and Claude Code • Some impacted the entire platform
This was not characteristic of a generic outage.
Instead, it strongly indicates model-level instability combined with imperfect isolation between tiers and serving pools.
That’s what happens when systems aren’t fully isolated.
Observation: Failures in one model or tier were able to propagate beyond their intended boundaries.
Contributing Factor: Sudden Change in Traffic Shape
The timing of these failures aligns with key product changes: • Sonnet 4.6 became the default model • 1M-token context was made broadly available • Rate limiting shifted to unified account-based limits
These modifications did more than just boost traffic.
They altered its essence.
In this environment:
A single request is no longer a consistent unit of load.
A short query and a 1M-token agent task impose fundamentally different demands on the system.
So here’s the key shift: Not every request costs the same anymore. A small chat and a long-running agent task are completely different beasts.
If your system treats them similarly… you’re going to feel it.
Observation: Load management systems were not sufficiently cost-aware.
Putting It All Together
Looking across all three phases, a consistent pattern emerges: • Control plane was too centralized • Stateful dependencies had excessive blast radius • Model serving lacked strong isolation across tiers • Load governance was not aligned with request complexity
This combination created a system where failures did not remain contained.
They cascaded.
What Could Have Helped
There are some obvious improvements that could have reduced the impact:
1. Strong control plane separation Authentication, sessions, and user state should not be able to degrade core model access.
2. Distributed or redundant state management Primary databases should not act as a single point of failure for critical paths.
3. Cell-based model serving Different models and user tiers should operate in isolated environments with strict boundaries.
4. Token-aware admission control Requests should be evaluated based on computational cost, not just request count.
5. Graceful degradation mechanisms Traffic should automatically fallback to stable models or reduced functionality instead of failing entirely.
6. Gradual rollout strategies Major changes in model defaults and usage patterns should be introduced incrementally with safeguards.
Conclusion: What This Actually Shows
This wasn’t about weak models. The models are clearly strong.
The issue is somewhere else.
Model capability has advanced faster than the infrastructure supporting it.
This is not unique to one company.
It reflects a broader industry transition: • Long-context interactions • Agent-style workflows • Continuous usage
And that transition changes everything about how systems need to be designed.
Final Thought
We’re building systems that are getting more powerful very quickly… and with great power comes great responsibility..!!!

So the real question is
As these systems become more capable and always-on… are we making them more reliable or just easier to break under the wrong kind of load?